
标准建模样本筛选流程
标准建模样本筛选流程
本流程是对 FZ/T 01144-2018《纺织品 纤维定量分析 近红外光谱法》测试方法里建模样品额外提出的要求。目的主要是以下几个方面:
1. 让建立的模型更加准确
2. 让建立的模型所用的样本统一化
3. 让建立的模型所用样本标准化
4. 让建模的方法标准化
5. 让建模的步骤流程化
FZ/T 01144-2018《纺织品 纤维定量分析 近红外光谱法》标准步骤为:
1. 样本的收集
2. 采集样本的图谱数据
3. 应用化学计量学软件对采集的图谱进行处理这里大概有以下内容
3.1. 剔除异常样本
3.2. 选择评价因子剔除预测偏差值大于标准要求的样本
3.3. 加入图谱的处理方法
3.4. 建立模型
我将之前在建模工作里的步骤全部转移至样本的筛选上,这样以后我们在设备更换、维修、新增的时候我们的建模工作就极为的便捷,那么我们这里所说的标准建模样本到底是什么标准又是怎么筛选呢?
标准建模样本:可用于建立模型的理想样本,成分的含量值和吸光度谱图完美对应的样本
标准建模样本的筛选步骤为:
1. 收集模型所需样本

2. 人工初步筛选均质样本

3. 用近红外对同一样本的正反面谱图进行对比,选出正反谱图重叠的或者图谱形态一致的
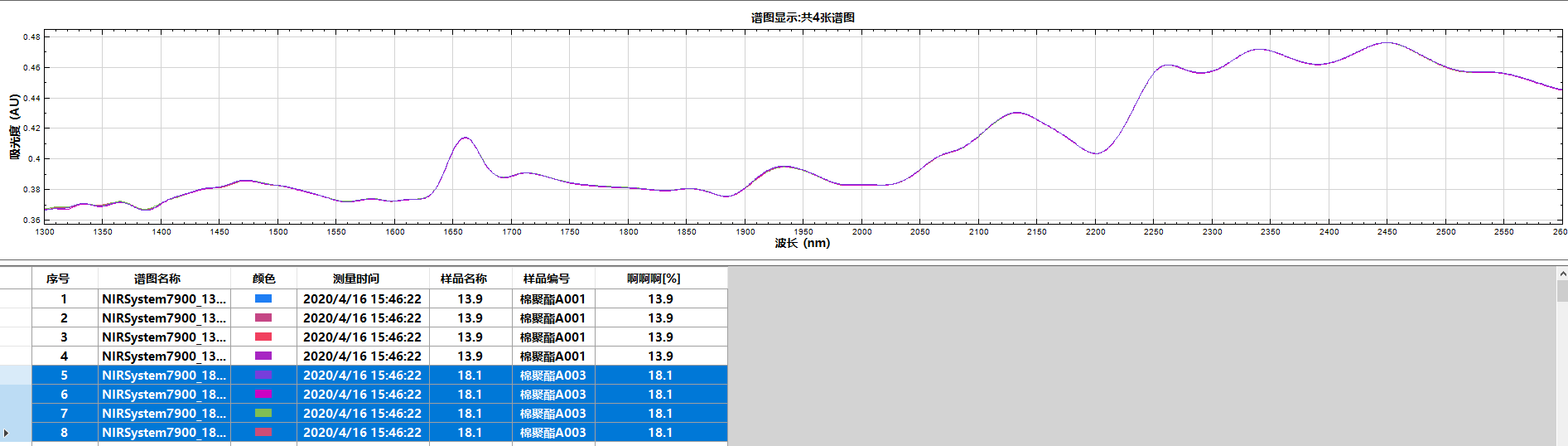
重叠谱图

形态一致谱图

有交叉谱图
4. 筛选出的样品编号扫图,应用建模软件对异常样本和预测偏值差超过标准要求的样本进行剔除,软件里剔除的同时将实际样品也剔除
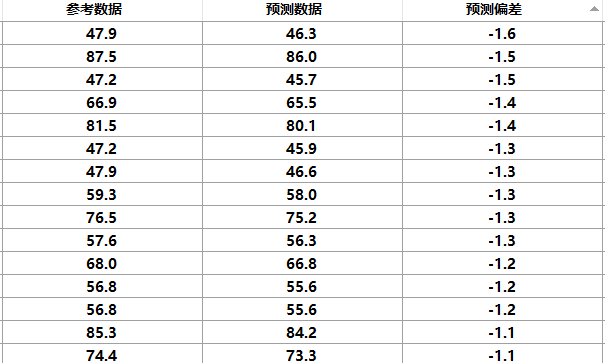
5. 补充被剔除的样本,循环第4步骤。若还有被剔除的样本那么再进行添加。直到不在出现异常样和预测偏差大于标准要求的样为止。
6. 建立模型
这里我们以棉聚酯为例,棉聚酯的建模成分范围为棉含量0-100%,那么我们需要收集500块左右的标准建模样本,以0.2%个点1块样本为标准(这里的收集比例是我们大量的实验数据总结出来的)那么假设我们经过各方征集得到了很多样本,首先人工判断和剔除掉不均质的样本,再从剩下的样本中选出我们所需比例的500个样本进行编号(001-500)扫图,然后用近红外设备对比每一块样本的正反面图谱,剔除掉异常和图谱形态不一致的样本然后补充样本,再用建模软件打开这500块样本的图谱,利用交互验证的办法找出预测偏差值大于标准要求的样本进行剔除(棉聚酯标准要求3%)在剔除预测偏差值剔除到什么要求,那么你的模型的精度就在什么范围内比如我把预测偏差大于2和小于2的全部剔除掉,那么最终的模型精度就是2点以内,棉聚酯我们按照标准要求剔除到3以内,被剔除的样本根据编号找出,然后用相同成分含量的样本补充进去,再看新补充进去的样本是否合适。直到这500块样本都在我们的要求之内时,那么加上算法及谱图的处理方法,最后出模型。这时我们手上的这500块样本就可以作为以后建立模型的标准建模样本,请妥善保管。